D2L
机器学习还是蛮有意思的啦,慢慢看,好好理解!
D2L
填充(padding)与步幅(stride)

一般来说,在上下一共填充 $P_h$ 行,在左右一共填充$P_w$行,输出形状是:
$$
(n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)
$$
设施$p_h=k_h-1$和$p_w=k_w-1$可以使得输入和输出有着相同的形状。
2.2
2.22 带我毕设的学姐出去了。。。要好久
x = torch.zeros(5,3,dtype=torch.long,device= ,requires_grad=)这样的指定大小张量创建方式是最完整的。
重点:我们可以用 shape 或者size()来获得Tensor 的形状:
1 | print(x.size()) |
返回的torch.Size其实是一个tuple
inplace版本数据操作
pytorch操作的inplace版本都有后缀,add_(x)等。
我们平时看到的 nn.ReLU(inplace=True)、nn.LeakyReLU(inplace=True),这些语句中的inplace是什么意思?
inplace=True指的是进行原地操作,选择进行原地覆盖运算。 比如 x+=1则是对原值x进行操作,然后将得到的结果又直接覆盖该值。y=x+5,x=y则不是对x的原地操作。inplace=True操作的好处就是可以节省运算内存,不用多储存其他无关变量。- 注意:当使用
inplace=True后,对于上层网络传递下来的tensor会直接进行修改,改变输入数据,具体意思如下面例子所示:
Eg. inplace=True操作 会修改输入数据。
1 | import torch |

改变形状!这个经常用
用view()改变tensor的形状
1 | y = x.view(15) |
顾名思义,view仅仅是改变了对这个张量的观察⻆度,即更改其中一个,另外一个也会跟着改变。
如果一定要得到一个副本再改变其形状,则需要先clone()一下,再使用view(),使用clone的另一个好处是会被记录在计算图中,即梯度会传回副本时也会传给源tensor。
tensor和numpy互相转化
共享内存方式:numpy() from_numpy()`,数组共享相同的内存(所以他们之间的转换很快),改变其中⼀一个时另⼀一个也会改变!!!
拷贝创建式:torch.tensor()。
tensor在GPU上
用方法to()可以实现数据的移动。
1 | if torch.cuda.is_available(): |
2.3 自动求梯度
3.2 线性回归 从零开始实现(很重要!)
咱们直接伴随着代码将思路
1 | import torch |
3.3 利用pytorch实现线性回归
我觉得,在机器学习代码的编写中,网络结构的设计固然重要,但是在实现层面上,各种数据处理啊,维度啊,切片啊,又是很复杂需要时间的,因此在看人家源码的时候,一定有必要看懂别人数据处理部分的代码。
TensorDataset和DataLoader
TensorDataset 可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。
1 | a = torch.tensor([[1,2],[1,3],[1,4],[1,5],[1,6]]) |
DataLoader则是分批次输出:
1 | train_loader = Data.DataLoader(c,batch_size=2,shuffle=True) |
这样一次就能取batch_size个数据了,并且data为一个列表,label为一个列表。
最终结果是为了分批次打包成 data :label的样子。
weight和bias的解释
在模型初始化的时候,会使用init.normal_来初始化,我一开始并不理解这个weight和bias是什么东西,看到我所初始化的Linear层有这两个参数,还以为是全连接层特有的,后面才发现,卷积啊其它的网络层都有这两个东西,那么它们到底是啥?且看这幅图片:

$o=w_1x_1+w_2x_2+b$
w和b不只是这个线性函数的的参数,而是输入层的细胞到下一层细胞的权重,只不过这里线性回归的网络太简单了,每个细胞没有再激活函数。
权重 weights
(w1,w2w3)是每个输入信号的权重值,以上面的(1x2x3)的例子来说,x1的权重可能是092,x2的权重可能是02,x3的权重可能是0.03。当然权重值相加之后可以不是1。
偏移 bias
还有个b是干吗的?一般的书或者博客上会告诉你那是因为Sy=wx+bs,b是偏移值,使得直线能够沿v轴上下移动。这是用结果来解释原因,并非b存在的真实原因。从生物学上解释,在脑神经细胞中,一定是输入信号的电平/电流大于某个临界值时,神经元细胞才会处于兴奋状态,这个b实际就是那个临界值。
1 | from pyexpat import features |
在整个示例代码中,有几个点需要注意记住下:
在feature初始化的时候,注意方式的不同带来的数据格式的不同,他们会影响后面数据处理的函数使用:
1
2features=torch.from_numpy(np.random.normal(0,1,(num_examples,num_inputs)))
features = torch.tensor(np.random.normal(0,1,(num_examples,num_inputs)), dtype=torch.float)在使用这种方法建立网络net之后,要得到其中某个网络层的参数:应该使用
net.linear而不是net[0]。
卷积神经网络
3.9中的操作:其实就是把$28\times28$的图像展开成长为784的向量,输入全连接层之中。
局限性: 1.消耗内存 2.本来相邻的像素,现在却距离很远。

LeNet
卷积层:识别图像的空间模式,线条+物体局部
池化:降低敏感性
池化的窗口大小和步幅一样,这样池化不会重叠
这一部分代码没有什么特殊的,就是在实现每个网络,我认为这一部分是理解Pytorch的很好的例子,在经历前面的基础之后,利用这个图和网络代码的结构,可以很好的理解
一个有意思的想法:

AlexNet

网络结构:
- 第一层 11×11的卷积:使用更大的框去捕获物体
- 第二层 5×5 卷积,后面卷积全部用3×3
- 第一、二、五卷积之后使用3×3,步幅为2的MAX池化
- 两个输出个数4096的全连接层
特点:
- sigmoid->ReLU,化简(梯度恒为1,能够持续有效训练)
- 丢弃法控制复杂度
- 图像增广,扩大数据集
VGG
核心思想:使用小的卷积层级联能够取得和大的卷积窗口同样的效果
如3个3×3代替一个7×7,2个3×3代替5×5,==能够在保证有相同感受野的情况下,提升了网络深度==
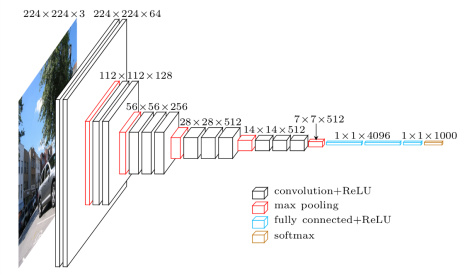
高和宽逐渐减半,而通道数每次翻倍,最后7×7×512的层传入全连接层。
1 | nn.MaxPool2d(kernel_size=2, stride=2)#这样的池化层会使得宽和高减半 |
一个小技巧:
下面构造一个高宽为224的单通道数据样本观察每一层的输出形状:
1 | net = vgg(conv_arch, fc_features, fc_hidden_units) |
其中named_children获取的是一级子模块及其名字,而named_modules返回所有的子模块,包括子模块的子模块
简单版的VGG:
1 | Sequential( |
NIN
1×1卷积层妙用!!!



