【机器学习】机器学习的分类——综述(更新中)
目录:
[TOC]
机器学习分类——综述
《A survey of ML to self organizing cellular networks》对整个SON,从应用上针对具体使用的不同方面来讨论了机器学习和SON的关系。但是相对来说对SON的介绍更多一些
接下来看《Artificial Neural Networks-Based Machine Learning for Wireless Networks_ A Tutorial》和《Deep Learning in Mobile and Wireless Networking A Survey》。前者对神经网络的介绍比较充分,对于建立框架来说更有价值一些。
《A survey of ML to self organizing cellular networks》读后感
机器学习应用到SON上的点,无非是从SON的整个构建过程来说的,在不同的时间不同的阶段,去解决在不同阶段的问题。
三个阶段——自动配置、自动组网、自动修复,我们先梳理一下在这三个阶段中可能遇到的问题。

文章一开始,给了机器学习的大致分类,认为还是很有价值的,


《Artificial Neural Networks-Based Machine Learning》读后感
由于整个通信领域从应用的角度分为很多部分,因此对于每个场景,都能够有ANN大展身手的时候,以下一一道来。
无线网络中的ANN
主要有两种:
感知环境——认知无线电;感知网络运行状态。最终达到智能预测
快速调节,智能分配资源(频谱资源、动态调整等),对于超密集无线网络的自组织管理。
另外物理层也有效——编码、调制。
对于ANN的大体分类

这部分已经大致介绍了各个神经网络的特点,并在下一部分进行具体描述。
递归神经网络
能够同时考虑当前和历史输入,很适合移动预测。输入又到输出不断递归,就好像好几个网络级联,同时因为时序的原因,考虑到了历史和当前的输入。
ESN
采用了存储池计算的思想,见最后。优点:中间的稀疏节点连接能够达到和其它网络一样的效果,并且只需要训练输出层,使得训练速度很快。
DNN
特点是有多层隐藏层,能够更深层地学习目标特征,但是会面对过拟合问题。
在无线网络中的应用
总体上:
1.预测:无线用户的移动,优化频率等资源的使用;网络运行的规律,从交通状态到各网络和通信的需求。
2.网络边缘——自组织,还是资源管理,用户连接。
在无人机中的应用:
1.训练使得无人机能够更好的前往需要的地方(感知),满足地面的高流量需求。
2.基于用户的移动模式预测。K均值聚类方法,彼此接近的用户被分组到一个聚类中,更容易确定无人机位置,分配资源。
(有点不懂你老惦记着你那无人机干嘛)
在VR中的应用
此时的VR不是在家电视面前带着眼睛打游戏的VR了,目标是在室外,通过无线链路进行画面的实时传输。因此VR——360°的信息,用户发送实时的用户位置和方向信息,需要极高数据率。所以对用户头部运动的跟踪需要极高的精度。
而VR中人工神经网络在识别和预测用户的动作和他们的行动方面是有效的。
已经:手势识别、交互式形状变化、视频转换、头部运动预测和资源分配。
还没有:稀缺的频谱资源、有限的数据速率以及如何准确可靠地传输跟踪数据。
VR必须考虑上下行链路的传输,实现服务质量。上下行链路之间的资源分配:最大化共同考虑了用户关联、上行链路资源分配和下行链路资源分配的耦合问题。同时还要考虑其它基站的资源分配——基于ESN的反向链路算法使每个基站能够以自组织方式分配下行链路和上行链路频谱资源,该自组织方式根据动态环境调整资源分配。(这里提到ESN的反向链路算法的优点是,它为网络提供了预测每个动作产生的虚拟现实服务质量值的能力(而不是像在Q学习中那样依赖于Q表来记录观察到的效用值,需要遍历所有动作)。
在无线虚拟现实应用中,对于信道选择和用户关联等问题,在反向链路算法中使用浅层神经网络可能更合适,而基于DNN的反向链路算法更适合功率分配。这是因为在功率分配问题中,优化变量是连续的。
SNN很好的处理快速变化的VR视频–>预测用户的动作如眼球和头部运动–>构建VR图像,减少延时。
在边缘计算中的应用
边缘计算面临的两大问题:移动边缘存储和计算——网络切片+雾计算。具体问题:计算布局、计算资源分配、计算任务分配、端到端延迟最小化以及设备能耗最小化。
边缘缓存的内容很大程度依赖对用户行为、位置的预测
1.预测用户的内容请求分布和频率。内容请求分发预测+移动模式预测
2.从收集的数据中寻找社会信息,社交网络预测用户下一步事件(用户兴趣、热点事件)
3.聚类,对用户分类,节约资源。
预测和聚类常常同时使用先分类,每个计算中心处理某个确定的任务。
ANN在分配计算资源中扮演很重要的角色,是一个多对多匹配问题,通过预测用户需求,分析历史信息,实现整体的移动边缘缓存和计算优化问题。
频谱管理
神经网络可以用于频谱资源的管理
现在终端都是拥有不同接入途径的(WWAN&WLAN)。在需要保持WiFi和LTE公平共存的LTE-U系统中,LSTM可以成为资源管理的有效工具。
LSTM在这一应用中带来的主要好处是,它使蜂窝系统能够准确预测未来无线网络的非高峰时段,从而抢占传输信道。并且其预测能力也能够很好的平衡这两者,更好的面对未来流量。
其中,深度架构对wifi预测好,浅层RNN对VR和无人机移动性数据够了,简单的神经网络(模糊神经网络)对物联网够了。
(P26页有个总结性的,可以一看)
在物联网的应用
有趣的一个方向:整个物联网被看作是神经网络,物联网设备看作节点,通过训练FNN优化网络,这种映射可以用来通过一组中继找到从发射机到接收机的最佳传输链路。
单独了解探索部分
以下为自己在看的过程中,对某些概念感兴趣,在知乎/CSDN/github自己了解的部分
强化学习 Reinforcement Learning
:key:对于强化学习还是没有概念,首先看这个
太难看,不好理解,看这个
或许会看书《人工智能 - 一种现代化方法》
强化学习的基本模型就是个体-环境的交互
- 下围棋——回合制/片段性任务——终止的时候给反馈$G_t=R_{t+1}+R_{t+1}+\ldots+R_T$
的,当然我们希望将其拆解,尽量把反馈给到每一步上
- 连续任务——衰减收益$G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}\ldots=\sum_{k=1}^{\infty}{\gamma^k R_{t+k+1}}$
,$\gamma$ 是衰减率(临近的收益更高)
通过时间差分学习 (Temporal Difference Learning) 来训练的。每一个时间步,都会有总结学习,等不到一集结束再分析结果。
强化学习的结果——**决策**,在$s$状态下执行动作$a$的概率$\pi(a|s) $
一个前提——符合马尔可夫决策过程
下一步的状态只与当前状态和马上采取的动作有关,不需要回溯、记忆(下围棋,知道现在棋面,准备哪里落子,就知道下一时刻的棋面)
马可夫性使得我们可以仅仅利用当前状态来估计接下来的收益——反馈的收益
强化学习三种方法
1.基于价值,Value Based
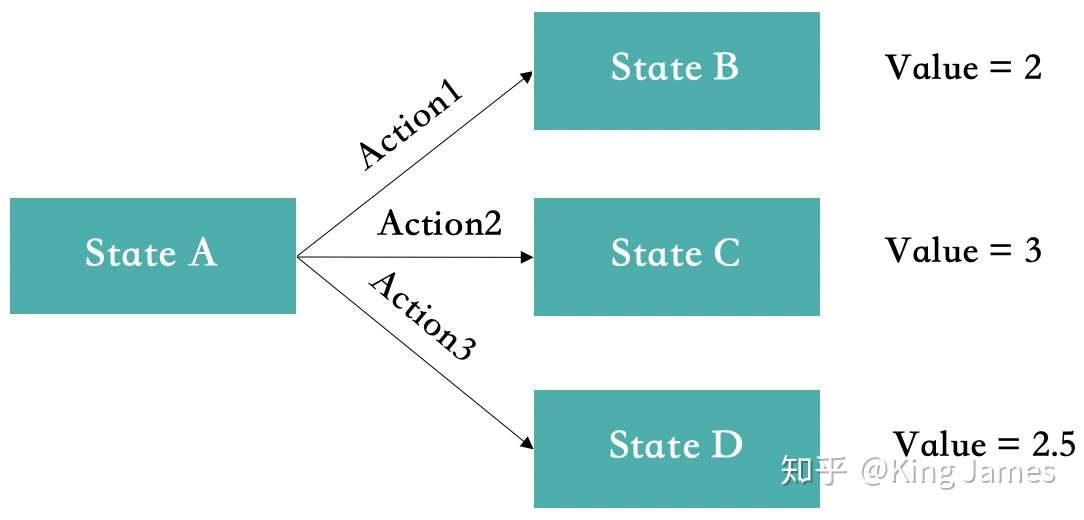
显然会选择anction2,当然这些Value提前是不知道的,通过不断尝试,和环节交互,获得Reward,最终得到一个稳定的Value。
缺点:动作空间是离散的,面对连续的运动难以拆解;最终学习完每个State对应的最佳Action基本固定。但有些场景即使最终学习完每个State对应的最佳Action也是随机的,比如剪刀石头布游戏,最佳策略就是各1/3的概率出剪刀/石头/布。
Q-Learning
状态和动作的组合是有限个的,可以得到一个$m\times n$行的表格,表示下一状态有$m\times n$种可能的Q表格。理论上我们只要根据Q表格找到当前位置下的最优动作。
最直观易懂的策略π(S)是根据Q表格来选择效用最大的动作(若两个动作效用值一样,如初始时某位置处效用值都为0,那就选第一个动作
但这样的选择可能会使Q陷入局部最优:在位置 S0处,在第一次选择了动作1(飞)并获取了 r1>0的奖赏后,算法将永远无法对动作2(不飞)进行更新,即使动作2最终会给出 r2>r1 的奖赏。
改进的策略为ε-greedy方法:每个状态以ε的概率进行探索,此时将随机选取飞或不飞,而剩下的1-ε的概率则进行开发,即按上述方法,选取当前状态下效用值较大的动作。就是模拟退火思想
当然,在一开始的训练的时候**$\varepsilon$**应该设置的更大一些,这样让模型更有探索性,否则没尝试过的antion一直是0。
更新Q表格:$Q(S,A)\leftarrow(1-\alpha)Q(S,A)+\alpha[R(S,a)+\gamma max_aQ(S’,a)]$
其中**$\alpha$为学习速率(learning rate),$\gamma$为折扣因子**(discount factor)。根据公式可以看出,学习速率α越大,保留之前训练的效果就越少。折扣因子γ越大,$max_aQ(S’,a)$所起到的作用就越大。但指$max_aQ(S’,a)$什么呢?
考虑小鸟在对状态进行更新时,会关心到眼前利益($R$),和记忆中的利益($max_aQ(S’,a)$)。
$max_aQ(S’,a)$是记忆中的利益。它是小鸟记忆里,新位置$S’$能给出的最大效用值。如果小鸟在过去的游戏中于位置$S’$的某个动作上吃过甜头(例如选择了某个动作之后获得了50的奖赏),这个公式就可以让它提早地得知这个消息,以便使下回再通过位置$S$时选择正确的动作继续进入这个吃甜头的位置$S’$。
可以看出,γ越大,小鸟就会越重视以往经验,越小,小鸟只重视眼前利益(R)。
SARSA
2.基于策略——Policy Based(个人认为是离散到连续的补充)
而基于策略的强化学习(Policy-based RL)则可以解决上述两个问题,这是直接对策略进行建模,即学习 $\pi_\theta(s,a)=p(a|s,\theta)$ ,给定状态$S$,会直接得到$\alpha$。显然离散分布的$\alpha$就可以满足离散问题,对于连续动作空间,可以先假设动作服从一个分布 ,比如高斯分布,那么可以从状态$S$输出个动作的均值$\alpha_\mu$,然后动作的选取可以利用$\alpha\sim N(\alpha_\mu,\sigma)$,
整个动作空间是一个概率的分布,虽然某个动作概率很小,但是仍然可能选中,选择动作A,然后回溯给reward,因此,更新Policy的Loss为$L(\theta)=\Sigma log\pi(a|s;\theta)f(s,a)$
其中f(s,a)是对s下动作a的评估。$log\pi(a|s;\theta)$ 就是log likelihood。假如评价比较高,那么动作A的概率就增加,以后就更大几率走A
3.Actor-Critic(将上面两种结合起来)
做一个强化学习的小程序似乎还挺好玩,如果可以的话有时间整一个——2021.7.21
监督学习
朴素贝叶斯
这里我们联系到朴素贝叶斯公式:
我们需要求p(嫁|(不帅、性格不好、身高矮、不上进),这是我们不知道的,但是通过朴素贝叶斯公式可以转化为好求的三个量
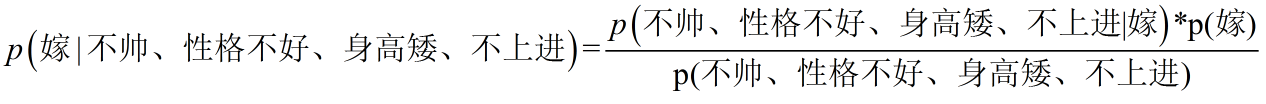
朴素:各个假设特征之间相互独立
一个问题:有些项缺失数据呢?
当分子在进行拆分的时候,如果训练量不足,很有可能遇到一个新的情况,那么在这时其中一项P(A|B)就是0,导致整个概率是0,这显然是错误的。
而这个错误的造成是由于训练量不足,会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准(这就引出了我们的拉普拉斯平滑),它的思想非常简单,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
拉普拉斯平滑——对每一项拆分都要进行这样的平滑,并不是只对为0的项。拉普拉斯平滑参考,以上是对特征值为离散,如长相(帅,不帅,非常帅)进行考虑的,此时每一项的概率容易数数统计出来。
另一个问题:特征值为连续函数呢?
实质:当样本很大的时候,取值连续依然可以用概率,或者近似概率进行求解。只是在样本很少的时候,没办法用概率估计,那此时我们就假设样本概率分布满足高斯分布,根据已有的数据计算均值和方差(每一类都有自己的分布都算出来),然后根据这个分布,带入要求的情况求出概率。
朴素贝叶斯的缺点:认为特征之间独立,和使用高斯分布作为概率分布,二者导致易出现误差
决策树
从刘华强买瓜到决策树思想2333333
blog的点
有一堆属性和样本,想要得到一个树
怎么生成树
怎么找到最优属性
分裂是什么
纯度、信息增益是什么
知道了二者然后要怎么做去划分
评价与剪枝
RNN(是怎么一步一步进化到后面的,把握时序)
SNN脉冲神经网络
这个讲的很有意思,从神经元的理念来说明问题所在,其对于发展的概括很有启发性
其与LSM的应用(LSM是一种使用脉冲神经网络(SNN)的储层计算机),还有ESN的发展,都是存储池计算
上面两者都适合对于时间序列建模,但是LSTM是更能够处理长期相关性的数据
LSTM长短期记忆网络
遇到的问题
大方向上:
1.机器学习有很多的分类,从不同角度上看又有很多分类的方法([传统机器学习、深度学习、强化学习],根据神经网络的不同来分[稀疏神经网络,深度神经网络,液态机,CNN],根据无线通信中的应用来分[环境频谱感知、编码调制、自组织、智能化管理]),那么究竟该怎样去学习呢。
2.读了综述然后该干什么,怎么样形成体系,因为如果要做思维导图进行分类,其实很简单并且已经有很多的参考。但是很深入某一个又好像不太符合目标,就像初学C语言一样面对一个成体系的东西,像一个球很难入手。
小细节上:
为什么要分批次训练;机器翻译有时候觉得调整之后通顺了自己能够读懂了,还要再改吗(有个论文60+页);



